At DiSSCo, our development process is user-centered. This ensures that every tool we build is tailored to the real-world workflows of the scientific community.
To bridge the gap between engineering and practical institutional needs, we established a number of key user groups for DiSSCover. These groups serve as a continuous validation mechanism for us. Rather than designing features based on assumptions, we use the feedback and insights from these users to test hypotheses, identify bottlenecks, and validate new concepts and features.
Simply put: we design and build with users, for users.
DiSSCover redesign
Recently we laid the architectural foundations for the redesign of the DiSSCover platform.
For this redesign, our focus is mainly on three core pillars:
- accessibility – ensuring WCAG 2.2 AA compliance, by implementing high-contrast color schemes and keyboard navigation, amongst many other things.
- responsiveness – seamless performance of our platform across all devices and screen sizes.
- workflow alignment – helping researchers and collection managers work faster and more easily in DiSSCover.
With these three pillars and feedback from our user groups in mind, we’ve been working on several new and improved DiSSCover features.
Specimen discovery
After the DiSSCo Showcase event in 2025, we sent out a survey to event participants, as well as existing DiSSCo users and interested parties. Our goal was to map out the biggest hurdles in specimen discovery and data curation. Amongst many other things, the results highlighted a clear demand for a more intuitive search interface, a more visual and clear specimen detail page, and AI-driven automation.
The demand for AI assistance in digitizing and curating specimens is a common one. In DiSSCo we support this through our Machine Annotated Services. It is great to see that the survey validated this user need.
We used feedback from both the survey and our user group to improve the layout and structure of the specimen detail page. Specimen images are now much larger and stay locked in view while you scroll through the details alongside them. We’re also tightly integrating DiSSCo’s annotation services and making pending annotations much easier to spot.
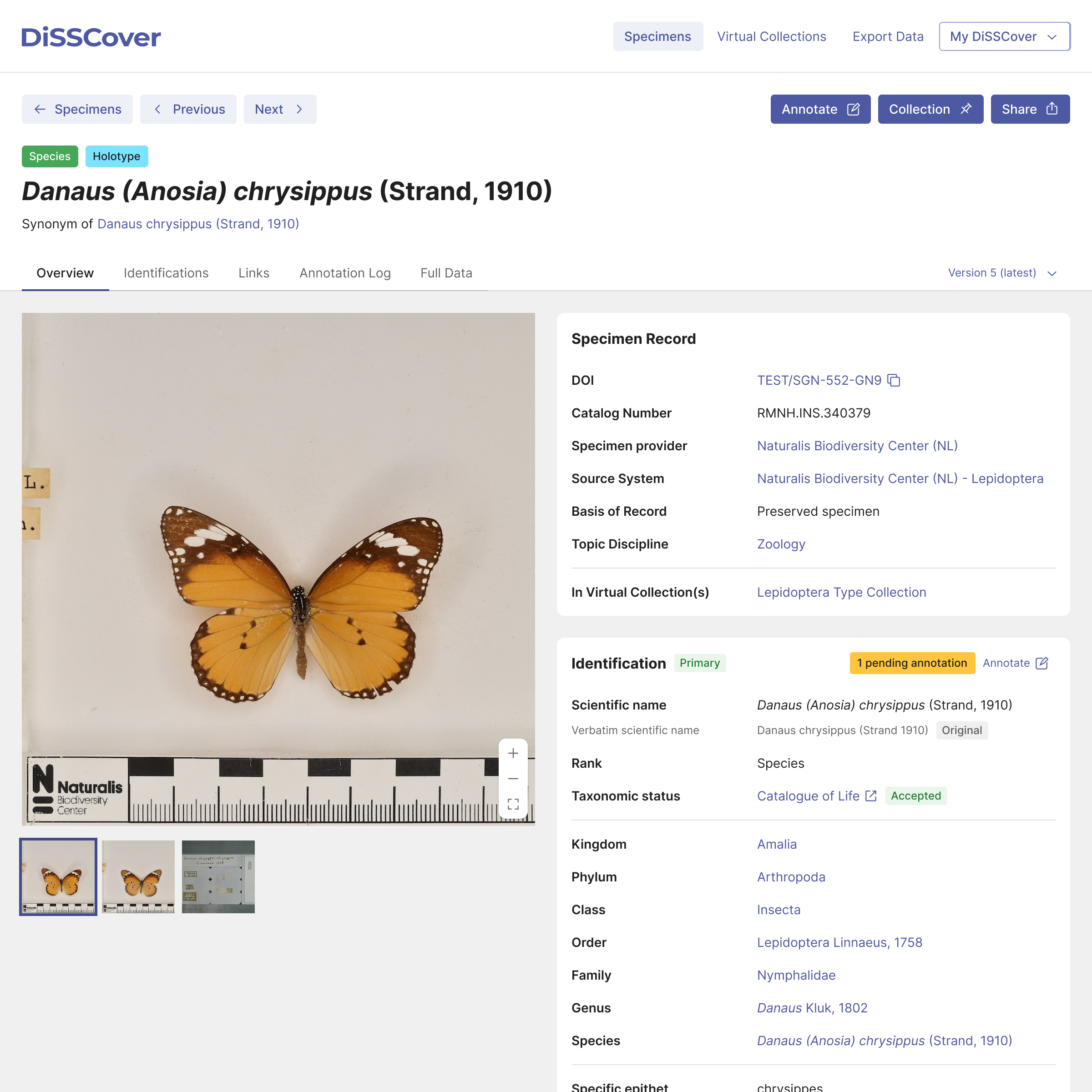
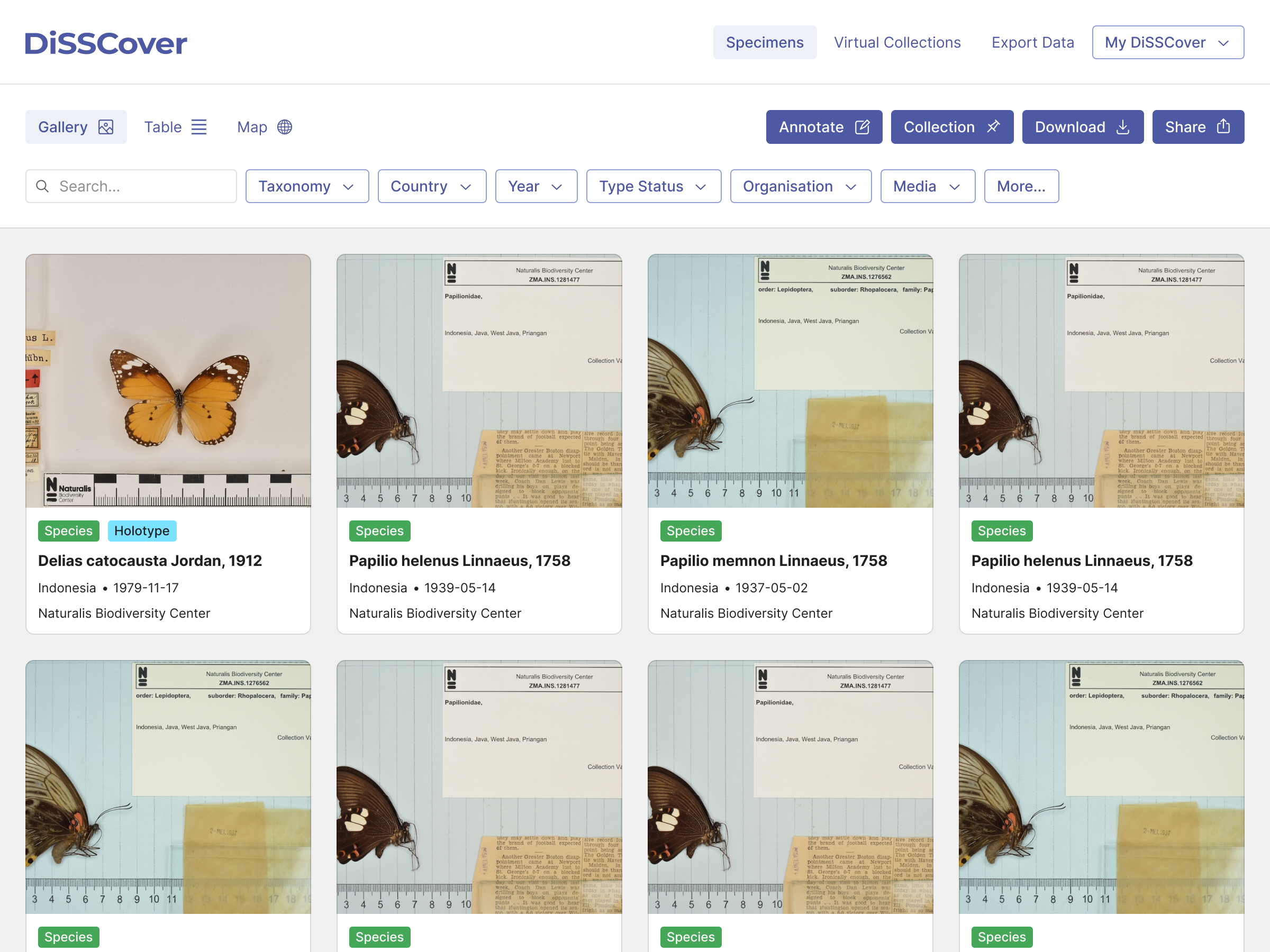
We also used insights from the survey to design an improved search experience. This has now become a flexible environment where you can easily filter data and switch between data grids and visual galleries.
Taxonomic annotations
Annotations are foundational to data enrichment, but the current workflow makes researchers navigate a set of dropdown menus to isolate specific taxonomic ranks. In cognitive psychology, this is known as high cognitive load. It forces the user to spend mental energy navigating UI mechanics rather than applying their expertise.
By leveraging the Catalogue of Life backbone within the interface, we formulated a new hypothesis: a single, predictive input field could replace the dropdowns system entirely. Researchers simply type part of a scientific name, and the API exposes all matches alongside their taxonomic ranks.
Our user group reviewed the prototype and saw a significant reduction in interface complexity and the time it took to complete this task.

Virtual collections
Our user group has also been very helpful in defining Virtual Collections, a new way to curate and share digital specimens online, across different biodiversity institutions.
Through a number of feedback sessions, researchers stated that filters for searching through digital specimen must include metadata geographic regions, country-level data, and specific biological attributes like specimen sex.

We also consulted with the user group to work on concepts for the Virtual Collection creation process. This resulted in a wizard-like approach where users can create Virtual Collection by following a couple of simple steps. We already have a couple of improvements on our radar as well, also based on early user feedback.
Finding the root problem behind the feedback
As we advance the DiSSCover platform, our design and development philosophy remains anchored in a fundamental product design truth:
“Users are the experts on where the system feels broken, but it’s our job to design the solution.”
Our role as user experience designers and developers is to look past the immediate complaint, diagnose the underlying issue, and come up with a solution that works for as many users as possible.
Of course, in a global infrastructure like DiSSCo, catering to diverse scientific disciplines means we cannot always design custom solutions for every individual need. Instead, we strive to build a system that brings predictable, inclusive, and powerful research tools to the entire scientific community.
In the months ahead, we will gradually implement and release new features and improvements for DiSSCover. We hope you will find them as useful as our user groups did!
Interested in joining our user groups and give feedback on early concepts? Great! Please get in touch with us.