
As the world is dealing with the outbreak of SARS-CoV-2 a great deal of effort has been focusing on data sharing, linking and open science in general. For instance the community around taxonomic research (see Joint CETAF-DiSSCo COVID-19 Task Force) is focusing on international collaborations to make use of data that can help us understand the origin and distribution of disease agent, host and vector. Initiatives like Virus Outbreak Network are working on FAIR data exchange. The research infrastructures that provide access to biodiversity, taxonomic, genomic and biotic interaction data thus are important technical components for researchers. However, in order for a comprehensive picture to emerge from the existing and new datasets, we also need to assess the current status of data repositories and research infrastructures. All these momentum around pandemic related research gives us a unique opportunity to reflect on current scope and future possibilities.
In this post, I comment on a recent paper (“Repositories for Taxonomic Data: Where We Are and What is Missing“; published online: 16 April 2020) in Systematic Biology that brings attention to lack of efforts in “safeguarding and subsequently mobilizing the considerable amount of original data generated during the process of naming 15–20,000 species every year”. This is a timely article that also aligns with various discussions around Advancing the Catalogue of the World’s Natural History Collections.
The article does an excellent job by first quantitatively assessing number of alpha-taxonomic studies. Then an impressive tabulation of items from manually screening 4178 alpha-taxonomic works (published in 2002, 2010, and 2018) to conclude:
..images are the most universal data type produced in alpha-taxonomic work. This is true of all regions of the world. As a conservative estimate, ten images may typically be produced of the holotype and paratypes of a new species and published as part of the taxonomic study. Mostly, these are photographs and drawings, sometimes scanning electron microscopy (SEM). We may assume that in comprehensive revisionary studies, up to 100 images (of comparative voucher specimens, or of different morphological characters) will be produced per newly named species. Most are probably neither published nor submitted to repositories.
Miralles, Aurélien, et al. “Repositories for Taxonomic Data: Where We Are and What is Missing.” Systematic Biology (2020).
Compared to the amount of feline images and videos that are abundant in the social media this is a very manageable volume for modern data infrastructures. But how are taxonomic data infrastructures FAIR-ing? The article provides some valuable information and guidance.
Surveying a number of generalist and specialist repositories (the list is in the appendix of the article) the article proposes “Criteria for taxonomic data repositories” with FAIR principles in mind:
Taxonomic data, repositories should be (i) free of charge for data contributors, (ii) user-friendly, with a low-complexity submission workflow, not requiring affiliation to academic institutions and not requiring cumbersome registration or login procedures, and (iii) including careful and prompt quality-checks of submissions by dedicated data curators.
The article also highlights the importance of specimen identifiers however points out various technical and organizational issues that still need to be addressed by the community. For instance, “…the International Code of Zoological Nomenclature does not require individual identifiers for type specimens.”

Some of these issues around alpha-taxonomy data mobilization have been raised before (see this 2019 opinion paper in the European Journal of Taxonomy). However the article argues that:
Despite innovations such as semantic markup or tagging, a method that assigns markers, or tags, to taxonomic names, gene sequences, localities, designations of nomenclatural novelties and so on (Penev et al. 2018), standardization and sharing of raw data is far from being widely implemented in taxonomy.
This provides a fruitful avenue to think about data infrastructure design and operation around alpha-taxonomy workflow. From the perspective of DiSSCo (where specimen based data, metadata, and persistent identifiers are core elements), the survey and conclusion presented in the article will be immensely useful to understand pluralistic and pragmatic user requirements as we are working with European museums and natural science collections to create a data-driven research infrastructure (where alpha-taxonomy data and related workflows are invaluable components).
The proposed concept of Digital Specimen builds and extends on existing ideas (cyberspecimen, cybertaxonomy and Extended Specimen Network mentioned in the article) by bringing in FAIR Digital Object and machine actionable services to the forefront. The goal is to augment and support taxonomic and other research capabilities by creating and maintaining a sustainable infrastructure (the article mentions the importance of perpetual data storage but also associated carbon footprint).
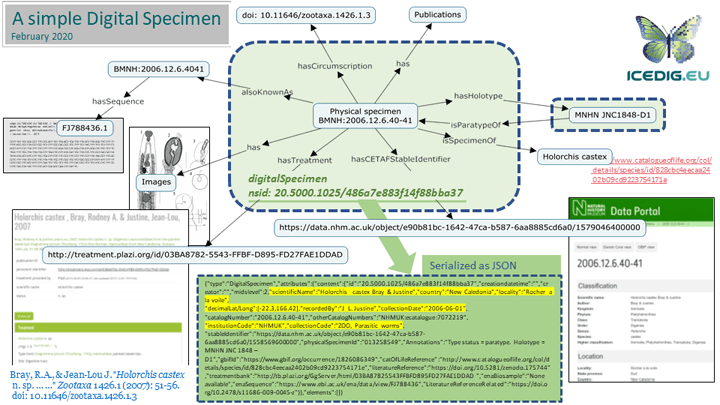
A few more links and recommendation for further reading. The article emphasises the centrality of images generated from alpha-taxonomy research. In this regard, interoperability frameworks such as IIIF are important initiative for workflow and data repositories (check also SYNTHESYS+ projects on IIIF). We also need to think about data contextualization and re-contextualization not just from a technical perspective but other dimensions as well. I recommend Data-Centric Biology: A Philosphical Study by Sabina Leonelli for a comprehensive philosophical context.
As the article aptly points out that “taxonomic assignments are quasi-facts for most biological disciplines” thus data re-use and linking need to accommodate not just innovative approaches such as integrated taxonomy and machine learning technique but also a pluralistic, human centric understanding as well. Works by Beckett Sterner and Nico Franz speak to this. Also check out the inaugural issue of Megataxa in particular the editorial entitled “Taxonomy needs pluralism, but a controlled and manageable one“.

{kind=link}