As the DiSSCo Transition Project (DTP) is in full swing, the DiSSCo Development team will be giving regularly updates on the progress. This progress will mainly focus on Task 3.1 – Further develop the piloted Digital Specimen Architecture (DSarch) into a minimum valuable product. However, as the development team is also involved on other tasks within DTP, as well as other projects such as BiCIKL and TETTRIs, we will also include updates on our work there.
In this first session, we gave a live demo on what the team has been developing in the last couple of months. After the demo, we had a short look at the roadmap and there was room for discussion. The group for this first session was relatively small, we would like to include a broader audience in the future.
The following topics were presented in the demo: — JSON schema’s exposed through https://schemas.dissco.tech/ — New version of openDS and annotations deployed on https://sandbox.dissco.tech/ — Deeper dive into Machine Annotation Service — Introduction of Machine Job Records — Development of generic taxonomic name resolution service, based on ChecklistBank data and GBIF matching algorithm — New icons for topicDiciplines and specimen — Discussions and new path forward with minting of DOIs with DataCite — TETTRIs marketplace mock-ups — A plan for a CETAF/DiSSCo Collection Registry
Looking forward to our next demo, which is now scheduled on the 24th of April, we hope to show the following topics: — Mint DOIs with DataCite — Integrate taxonomic name resolution service in ingestion process — Batch annotation for Machine Annotation Service v1 — Landing pages for Source Systems, Mappings and Machine Annotation Services — New filter options, especially for searches on taxonomy — Scheduling and automatic triggering of translator services based on cron — Update MIDS calculation to the latest version — Virtual Collections (stored searches, mutable) — Infrastructural upgrades — Centralised logging and monitoring solution — Automated auto-scaling of EC2 instances (Karpeter)
DiSSCo envisions discovering the untapped value within vast natural science collections across Europe and aims to connect these collections to related datasets and new insights using the FAIR Digital Object (FDO) framework. A key milestone toward this vision is the development of various data models and services that can help annotate and publish digital specimen data. This allows for the enrichment, correction, and improvement of digital specimen information, not only through manual annotation but also with batch and AI-assisted services.
During our design and test phase, we considered how these new annotation digital objects can integrate into the existing biodiversity data ecosystem. We align with ongoing discussions on open Digital Specimen (openDS) and MIDS, emphasising FAIR implementation. This approach ensures seamless collaboration and leverages existing models, ontologies, and specifications.
Now, let’s delve into the background, showcase an example, and explore the data model.
The concept of web annotation or scientific data annotation is not new. The World Wide Web Consortium (W3C) annotation data model (WADM), at the forefront of this collaborative endeavour, establishes the foundation. Drawing inspiration from the International Image Interoperability Framework (IIIF) and Europeana Annotation Data Model, both of which also build upon the W3C framework, we adopted WADM as our starting point. This ensures that annotations in the biodiversity domain align with global standards, fostering interoperability and enriching the scholarly landscape.
The topic of annotation regarding natural science collection and biodiversity data is also not new. The community has been working on this from various perspectives (see activities of TDWG Annotation IG, tools like AnnoSys,Pensoft Annotator; also see recent publications like Morris et al. 2023, Stork et al. 2019). Our approach builds upon these previous works, emphasising FAIR implementation and FDO Framework.
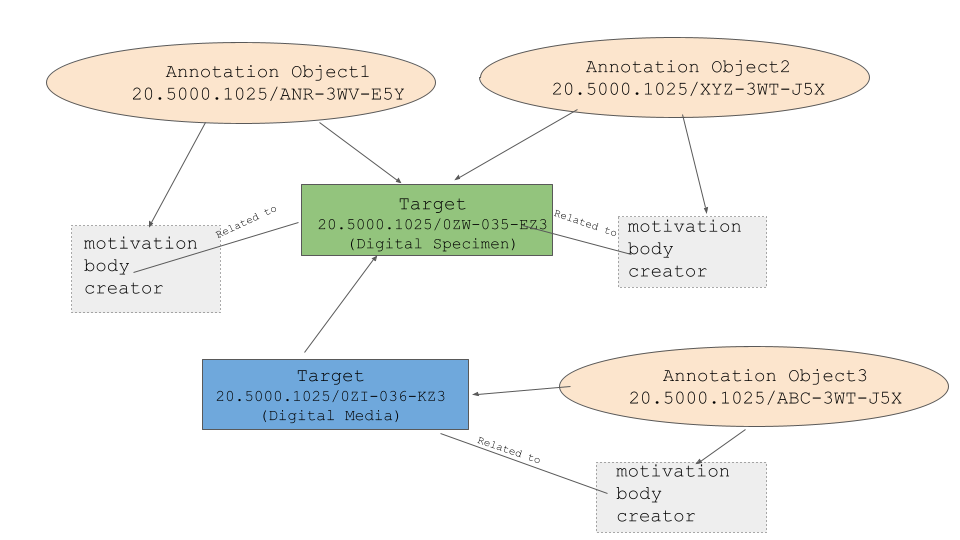
In Fig 1, we see the core WADM framework, which serves as the starting point for thinking about how annotation and digital specimens can be integrated. Annotation is always carried out on something — the “target” in Fig 1. In DiSSCo’s case, the target can be a digital specimen, a media object, or another annotation object. The body represents the content of the annotation and these components are linked.
Fig 1: The W3C Annotation Data Model (WADM) framework
Let’s consider an example involving a herbarium specimen (Fig 2), where a deep learning model can be employed to annotate and detect plant organs. Each of these boxes can serve as part of the annotation target. Picture a user drawing a bounding box, adding comments or making corrections to the content. This process can be applied to images or various data points such as collector’s names and locations. Additionally, we aim to accommodate both single-user interactions and batch processing. Our current sandbox implementation includes some of these features, ready for testing, and we hope to iteratively enhance them.
Fig 2: Annotation of a herbarium specimen organ detection
However, we need a framework — a data model — to capture annotations alongside specimen data and ensure FAIRness. Specifically, we need a flexible approach that accommodates commenting, editing, and data improvement. Fig 2 above illustrates the overall structure of our Annotation data model, incorporating concepts such as motivation, target, body, creator, and generator from WADM, and AggregateRating from schema.org. We introduce a few new terms as needed.
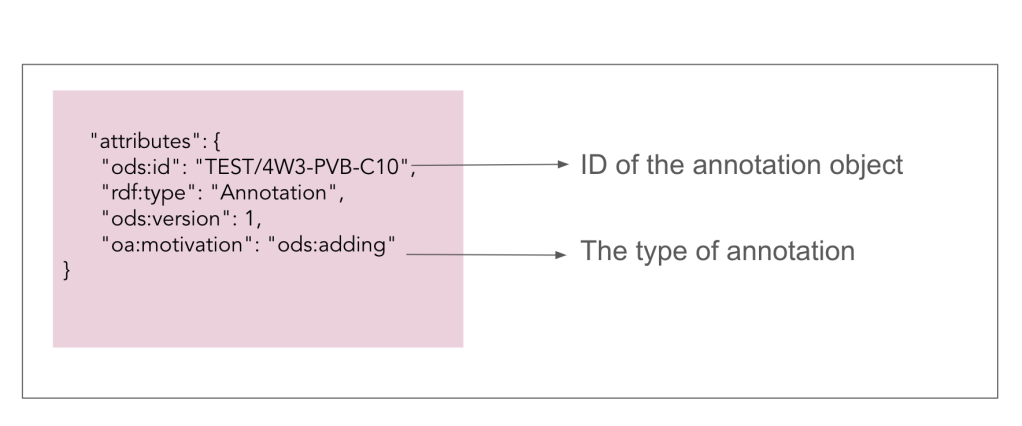
Let’s delve into this model in more detail. Picture a LEGO set, each piece designed to contribute to the grand structure. In Fig 3, observe the unique identifier (ID), type, and motivation of the annotation — defining its essence and purpose within the structure.
Fig 3: Identifier, type, and motivation
Fig 4 shows a crucial element: the target of the annotation — essentially, the object being annotated. This could be an entire image, a digital specimen, or a specific field.
Fig 4: The target and the selected field.
Finally, in Fig 5, there’s the body — the content encapsulated within the Annotation object. Here, we showcase the value — this could be an addition, comment, or an assessment (based on the selected motivation displayed in Fig 3). Another crucial aspect for tracking provenance is identifying who created this annotation — this could be a human or a machine agent.
Fig 5: The value and the creator
Our model is designed with flexibility in mind to capture different types of annotations. We are also planning to integrates this into approval/rejection workflows. Additionally, this structure facilitates linking and exporting of data to various systems, whether through bulk export or API operations. This adaptability ensures our annotation framework is versatile and aligns with diverse operational needs and collaborative workflows.
This process of data modeling and design is a collective effort. Many thanks to the core DiSSCo development team at Naturalis Biodiversity Center (Wouter Addink, Sam Leeflang, Soulaine Theocharides, Tom Dijkema). We also gathered responses through an RFC (Request for Comments) process, where feedback and insights shaped our thinking, paving the way for further improvement. Excitingly, several new features are in the pipeline. For more details, check out our GitHub and sandbox. Happy annotating!
In this post, we would like to update you on some of the recent technical advancements that we have made. Our team has been working tirelessly on various aspects including PID infrastructure development, data modeling work, and both frontend and backend development of the DiSSCover interface. These updates have allowed us to enhance the functionality and overall user experience. These are significant steps toward realising the vision of DiSSCo.
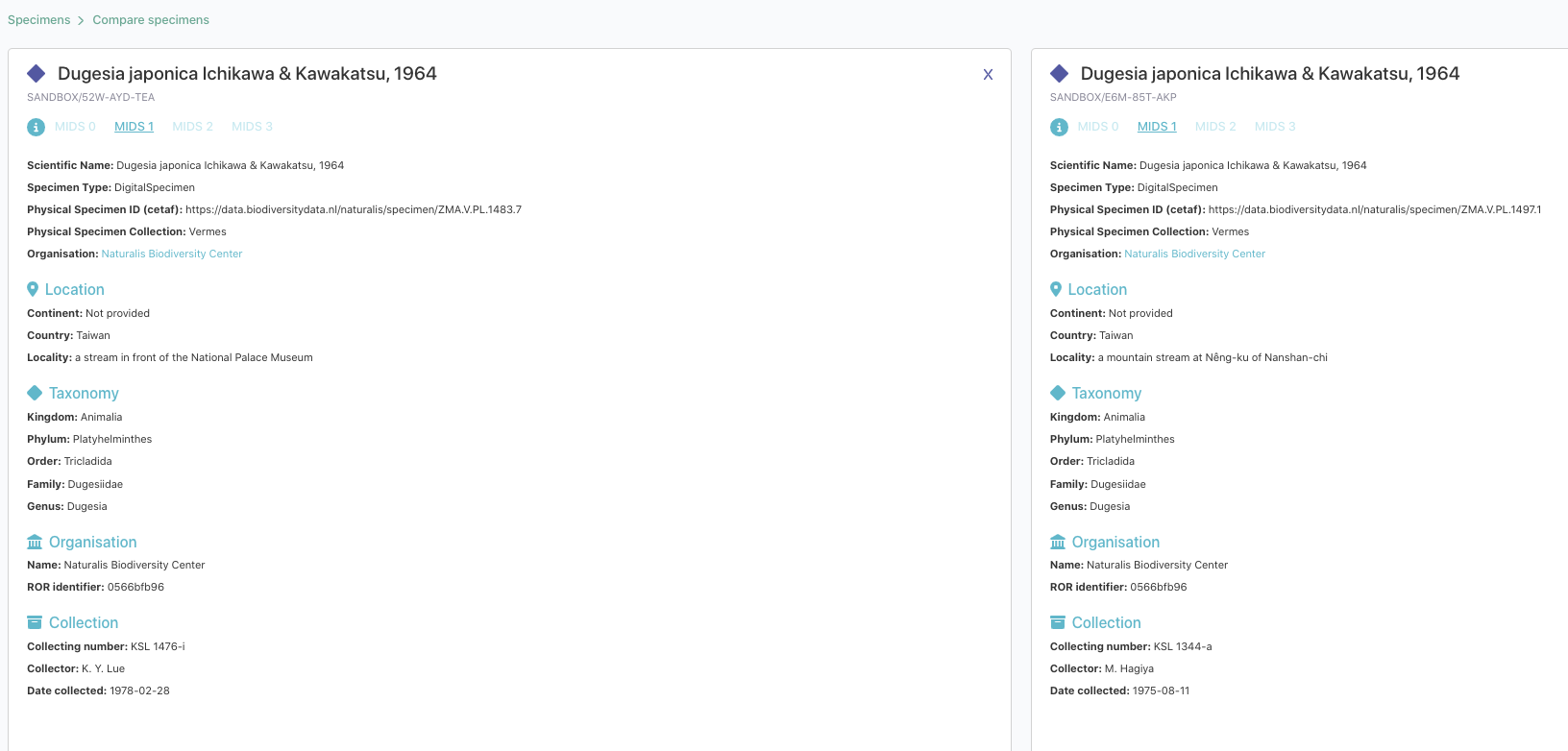
DiSSCover Sandbox interface: Our DiSSCo sandbox has gone through several iterations (both front and backend). We added different search, filter and compare features to easily find the Digital Specimens:
We also created a user onboarding tool to guide you through these features. Please let us know and use Github to send feedback.
Authentication: With the help of our partner at GRNET, we have incorporated ORCID and institutional login (with Keycloak). We are now working on the user onboarding workflow, login policy, and authorisation matrix.
Annotation: After authentication, the user can annotate either a full Digital Specimen record or a specific field. We have done work on creating a new Annotation data model (see the latest version of the Annotation JSON schema ). An RFC has been sent out to the community for feedback. We have made an effort to incorporate the W3C Web Annotation data model to use concepts such as Target, body, and motivation. Our current implementation allows for creating annotations based on this schema and these annotations are created as FAIR Digital Objects (with PID and FDO Records). We are working on adding a batch feature and also a scoring and trust model.
Data Harmonisation and GBIF Unified Data Model: As we have different data standards, formats, and terms, they introduce issues in the data lifecycle. This has an impact on data quality and building trust between data providers and consumers. So from the beginning, we are aware of the pitfalls and have made significant efforts in term/vocabulary harmonisation by reusing existing namespaces and ontologies as much as possible. We are also working closely with the GBIF Unified Data Model and the TDWG MIDS specification to incorporate these elements into openDS. When a new Digital Specimen is created, this approach can help us connect and move objects between different platforms easily. For example, the GBIF data model has an “EntityRelationship” component that provides a way to make connections between different entities. Instead of creating our own entity relationship model, we have incorporated it within the Digital Specimen data structure. Here is a snippet of our JSON serialisation that shows openDS attributes (ods), combined with Darwin Core (dwc) and also elements from the GBIF data model. Even though in this example, our initial sandbox implementation is duplicating some items (such as the ROR for the institutionId), the idea is that we now have a structure to build upon and add relevant, newly discovered links for the Digital Specimen thus making it a dynamic, actionable object.
IIIF Support and Image Annotation: As IIIF is a well-established community standard for image interoperability, we are working on support for that in our sandbox. There are different types of media objects linked to the specimen. We are also working image annotation feature which will align with the current annotation data model.
Persistent Identifiers and DOI infrastructure: A lot is going on in this area, as PID is one of the core components for DiSSCo infrastructure and FAIR implementation. Please see our other blog post that talks about the test PID infrastructure for more technical details.
Biodiversity Digital Twin Project and FAIR Digital Objects: One of the design principle we are trying to adhere is to re-use existing components and also thinking about cross project and cross research infrastructure alignment. This way we avoid duplication of efforts. The FAIR Digital Object (FDO) work within the BioDT project is a great example of this. We are now working on creating FDO Profiles for different Digital Objects that will be part of BioDT (similar to the DiSSCo FDO Profile). This is to understand how FDO can fit into the BioDT project as an abstraction layer between different infrastructures. The main benefit of this approach is achieving interoperability as different datasets and models will be needed to create digital twins.
Conference presentations, hackathon, and publications
A DiSSCo poster was featured at the First Conference on Research Data Infrastructure (CoRDI). At the conference, we presented some of the lessons learned during the design and preparatory phases of DiSSCo. You can view the poster online on the Zenodo platform.
We are actively engaged in the global discussion about the implications of the FAIR Digital Object paradigm for biodiversity research. A new paper proposes leveraging the FAIR Digital Object framework to advance the global vision of the Digital Extended Specimen concept. This paper emerged from discussions that took place at the 2022 FAIR Digital Object Forum conference. We are eagerly anticipating the 2024 FDO conference in Berlin. We are also excited about the upcoming 2024 FDO conference in Berlin.
This week, we are participating in the Elixir biohackathon, where we will be exploring improved linking from sequence data to specimen and sample repositories.
Keep an eye on our GitHub page and stay tuned for more updates.
Bringing together collections data from hundreds of sources requires sophisticated coordination. How do we track provenance, annotate, and reference all these Digital Specimens? Using globally resolvable Persistent Identifiers, or PIDs. We’ve discussed our PID infrastructure before on this blog. In this blog post, we will describe an exciting new update: the potential to upgrade our identifiers to DOIs. We’ll discuss what DOIs are, what our technical stack looks like, and what this means for the future of Digital Specimens.
Persistent Identifiers are a key component of the FAIRness of the DiSSCo infrastructure, allowing machines and humans to consistently reference, annotate, and cite Digital Specimens from natural history collections across the world. These identifiers are globally unique and assigned to a specimen upon ingestion into DiSSCo – no need to worry if two institutions both call one of their specimens “REPTILE.1”. In DiSSCo, a machine or human user can unambiguously identify any specimen. PIDs also provide stable references to a given resource – even if the resource in question has moved.
Handles and DOIs
So far, we’ve used Handles as PIDs for all our digital objects. The Handle System is a tool developed by CNRI for managing and resolving PIDs. It’s a distributed system, meaning DiSSCo is part of a global PID infrastructure. We manage our own handle infrastructure that communicates with the Global Handle Registry, which controls the resolution of all Handles.
The Handle System is a powerful tool to create globally resolvable identifiers, but Handles alone aren’t persistent. To put the “P” in PID, we need DOIs, or Digital Object Identifiers. DOIs are Handles with guaranteed persistence, which makes them a reliable tool for citation and provenance. You can identify a DOI by its prefix beginning with “10.XXX”.
The DOI Foundation governs the DOI system, ensuring once a DOI is minted, it stays up, regardless of whether or not the original institution exists or not. We want to use DOIs as identifiers for Digital Specimens and Media Objects to facilitate citation and persistent referencing of our resources. There’s a catch, however: only trusted organisations, called Registration Agencies (RAs), can mint DOIs. These organisations form a community dedicated to persistent, reliable identifiers. While it’s unclear whether or not DiSSCo will establish a new RA or partner with an existing one, we do know that we’ll need to set up comprehensive DOI infrastructure.
DOI Infrastructure
In this section, we’ll go over our preliminary DOI infrastructure. Code referenced in this section is all available on our GitHub:
Our first step was to provision resources on AWS. To do so, we used Terraform, an Infrastructure as Code (IaC) tool that lets us describe exactly what resources we want deployed on the cloud. By using IaC, we can easily manage complex infrastructure and track any changes through version control.
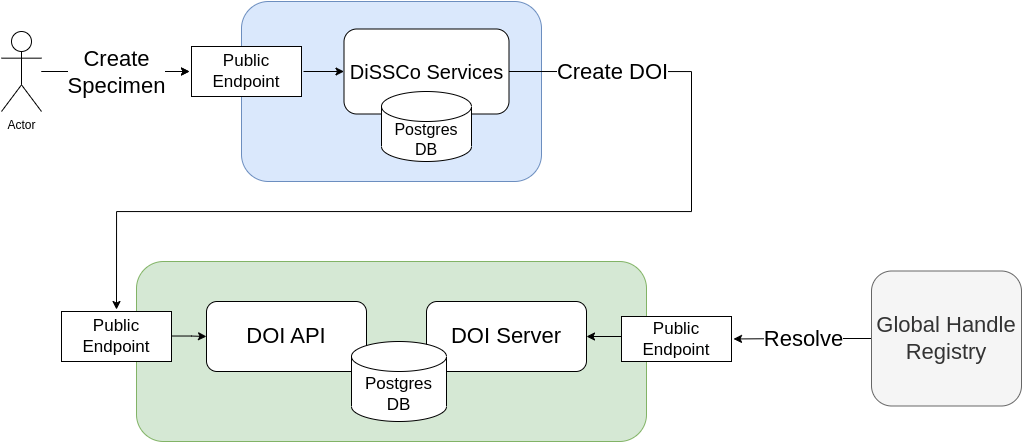
For the DOI infrastructure, our setup is relatively simple: a compute instance connected to a PostgreSQL database, all within a controlled private network. The DOI infrastructure was made completely independent from the rest of DiSSCo infrastructure by design; this will allow whatever RA mints DOIs for Digital Specimens to serve the wider collections community, rather than just DiSSCo. Because we’ve used Infrastructure as Code, we can easily transfer ownership to another organisation if need arises.
Containerized Applications
Once our cloud infrastructure was set up, we containerized the applications we needed to run our DOI system. We set up a handle server, which acts as the resolution system for our DOIs. We also containerized our Identifier Manager API, which allows us to quickly create batches of identifiers. The DiSSCo Infrastructure connects to the API via a secured public endpoint. The API and the server use the same PostgreSQL database as storage. Essentially, the API acts as our writer, and the handle Server exposes the contents of this database to the Global Handle Registry.
With all the containerized applications (plus a handy Nginx proxy setup and Let’s Encrypt-issued SSL certificates), the system looks like this:
An actor looking to publish a Digital Specimen may do so through DiSSCo services. DiSSCo services call our DOI API endpoint, which publishes the record (including the FDO Profile!) to the DOI database. Anything published to that database can be looked up by the global handle infrastructure, allowing the identifiers to be resolved.
What’s Next?
This test setup demonstrates that DiSSCo is capable of developing and maintaining reliable DOI infrastructure. While we’re not quite ready for permanent specimen data, this is a step in the right direction towards FAIR and FAIR Digital Objects implementation. As our infrastructure develops and our data model matures, we’re getting closer to linking and annotating collections data across DiSSCo partners.
In the realm of biodiversity and geoscience research, the digitization of natural history collections has revolutionized the way we study and understand our planet’s rich biological and geological heritage. However, as the volume of digitization and other valuable data resources continues to grow, ensuring their long-term accessibility and interoperability becomes increasingly challenging. This is where Persistent Identifiers (PIDs) come into play, providing a robust and reliable solution for managing and referencing these digital assets. FAIR Digital Object Profiles (FDO Profiles) further standardize and structure PID records, facilitating interoperability between FDOs and sophisticated machine actionability.
In this blog post, we will explore the significance of PIDs in biodiversity research, highlight the role of FDO Profiles in shaping the PID architecture of DiSSCo, and outline the design process of our first FDO Profile, now available for public feedback.
The Importance of Persistent Identifiers
PIDs assign globally unique identifiers to objects, providing a stable reference even if the objects are relocated or undergo changes. By ensuring persistence, PIDs eliminate broken links and guarantee the accessibility of digital resources, regardless of any future changes in storage infrastructure or hosting platforms.
When a specimen record is ingested into DiSSCo, it is assigned a PID. Through robust PID infrastructure, researchers, machines, and the wider community will be able to easily locate and cite specific Digital Specimens or related resources, enhancing transparency and reproducibility in research.
What is an FDO Profile?
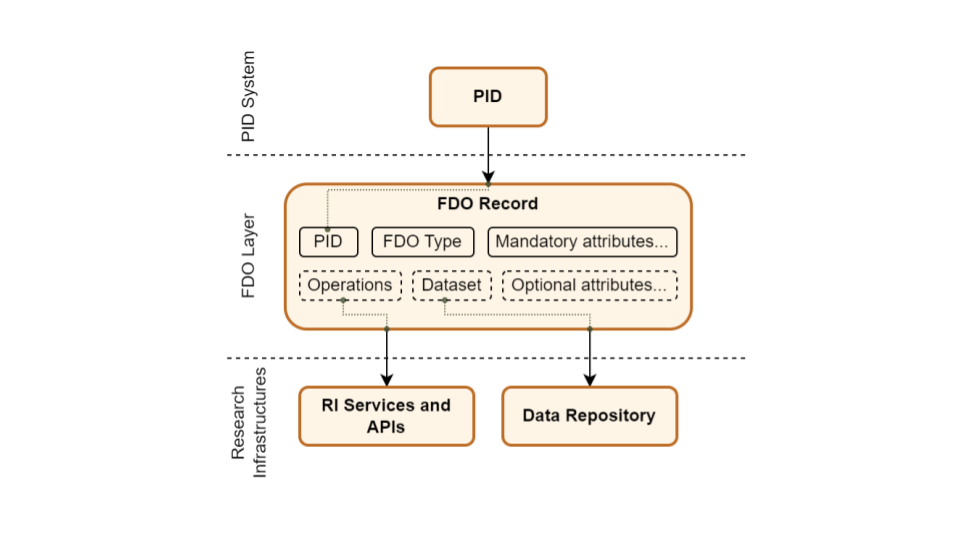
In addition to the location of the referenced object, FDO Records contain structured metadata that describes the attributes and characteristics of the resource associated with the PID. The FDO Record is similar to the PID record idea proposed by RDA [1], but the term FDO Record is used to “highlight that there could be possible [implementations] of FDO without explicitly relying on the attributes stored in a PID record” [2]. This metadata may include information such as title, creator, date, identifiers for related objects, access rights, and more. This information allows machines to make decisions regarding the Digital Object without needing to resolve the PID.
Different Types of Digital Objects have different FDO Record metadata requirements, and thus the actions a machine can take on a PID record is defined by the object Type. FDO Profiles standardize which FDO record attributes should be associated with each Type of object. Within DiSSCo alone, we expect to assign PIDs to a diverse array of object Types, including media objects, annotations, and of course, Digital Specimens. Each of these object types will have their own FDO Profile; currently, the FDO profile for Digital Specimens is available for public feedback.
FDO Profiles and DiSSCo
Recognizing the need for consistency and harmonization, our FDO profiles incorporate elements that can be reused for various Digital Object types within DiSSCo. Attributes like issue date or PID status are applicable not only to Digital Specimens but also to media objects, annotations, and other resource types. This consistency promotes interoperability and simplifies metadata management efforts.
Subsequently, we added additional attributes specific to Digital Specimens, such as specimen host and material sample type. This approach strikes a balance between standardized metadata representation across biodiversity research resources while accommodating the unique characteristics of Digital Specimens.
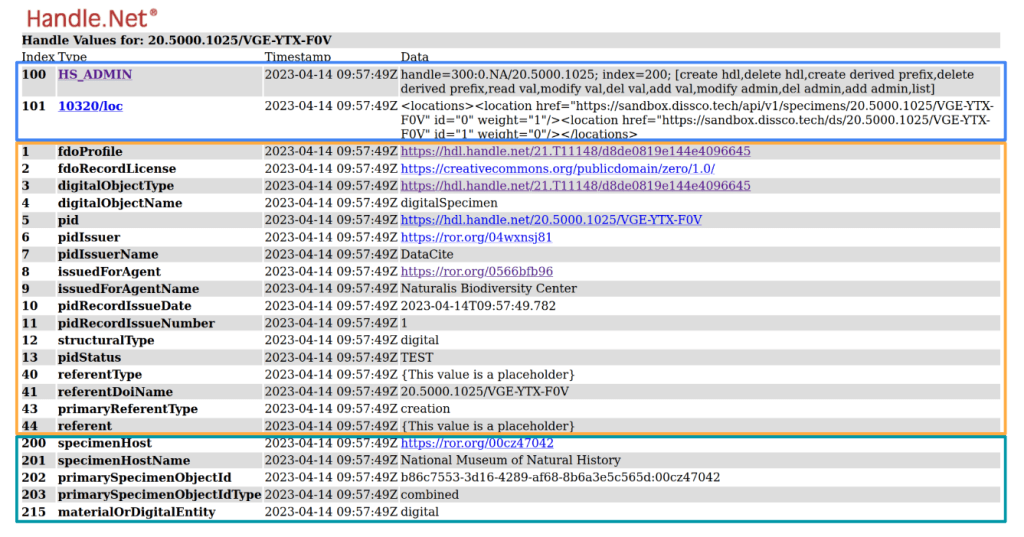
Sample FDO Record. 100-series indexes (blue) are reserved for administration; 01-099 indexes (orange) are applicable to all objects within DiSSCo; and 200-series indexes (teal) are specific to Digital Specimens.
Next Steps
We are actively working on designing additional FDO profiles for different Digital Object Types within DiSSCo. These profiles will further enhance the interoperability and standardization of biodiversity research resources, ensuring that the benefits of PIDs and FDO profiles extend beyond Digital Specimens to encompass various data types and formats.
We are actively seeking feedback from the community on the current FDO Profile for Digital Specimens via an RFC Document, available here. The RFC (Request for Comments) process facilitates conversation between DiSSCo and community members, provides an opportunity to receive feedback on the DiSSCo development process, and defines how decision making works. More information on the RFC process itself can be found here.
Conclusion
Persistent Identifiers and FDO profiles are crucial components of the DiSSCo infrastructure. By providing stable and globally unique identifiers, PIDs ensure the accessibility, citation, and long-term preservation of Digital Objects. Meanwhile, FDO profiles offer a means to describe the attributes of these PID records in a standardized and interoperable manner. As digitization efforts expand, leveraging PIDs and FDO Profiles will continue to play a pivotal role in unlocking the vast potential of biodiversity research, enabling collaboration, discovery, and machine actionability.
[1] RDA PID KI. 2019. RDA Recommendation on PID Kernel Information. Research Data Alliance. [Online]. DOI: https://doi.org/10.15497/RDA00031
[2] S. Islam, “FAIR digital objects, persistent identifiers and machine actionability,” FAIR Connect. [Online]. DOI: https://doi.org/10.3233/FC-230001
On Dec 19, after hours of negotiations and discussions, nations (except the U.S. and the Vatican) agreed to protect 30% of the planet for nature by 2030 (also known as the 30 x 30 agreement). The post-2020 Global Biodiversity Framework has been proclaimed both as a historic decision and also as a missed opportunity to protect Indigenous peoples’ rights. The full Kunming – Montreal (COP15) documents can be found on the Convention on Biological Diversity (CBD) site.
Excellent reporting, live tweeting, and summary threads about the event chronicled some of the ups and downs of the event with opinions. There was also a statement released by Ursula von der Leyen, president of the European Commission. The full statement is here.
I welcome the historic outcome of #COP15. The world has agreed on unprecedented and measurable nature protection and restoration goals and on a Global Biodiversity Fund.
And investing into nature also means fighting climate change.
This post is a preliminary take on what this framework means for research infrastructures like DiSSCo that are enabling the collection, storage, and dissemination of biodiversity data. These data (which include natural science collections) are critical for a wide range of research purposes, including monitoring and assessment of the status of biodiversity, identification of conservation priorities, and the development of management and conservation strategies.
The framework outlines 4 goals and 23 targets. In the 4 goals, the terms “data” and “infrastructure” are not explicitly mentioned. However, Goal C mentions digital sequence information on genetic resources:
The monetary and non-monetary benefits from the utilization of genetic resources, and digital sequence information on genetic resources, and of traditional knowledge associated with genetic resources, as applicable, are shared fairly and equitably, including, as appropriate with indigenous peoples and local communities, and substantially increased by 2050, while ensuring traditional knowledge associated with genetic resources is appropriately protected, thereby contributing to the conservation and sustainable use of biodiversity, in accordance with internationally agreed access and benefit-sharing instruments.
The link to genetic information is an important component for DiSSCo and also a focus for projects like BiCIKL and Biodiversity Genomics Europe. However, some of the granularity of this Goal needs to be outlined carefully. Is Nagoya protocol enough? Are genetic resources in any digital form or format applicable here? How do we measure fair and equitable sharing in the digital realm? These questions are not new but now we have a new target to think about.
Goal D talks about technical and scientific cooperation which is one of the primary services provided by various research infrastructures.
Adequate means of implementation, including financial resources, capacity-building, technical and scientific cooperation, and access to and transfer of technology to fully implement the post-2020 global biodiversity framework are secured and equitably accessible to all Parties, especially developing countries, in particular the least developed countries and small island developing States, as well as countries with economies in transition, progressively closing the biodiversity finance gap of 700 billion dollars per year, and aligning financial flows with the post-2020 Global Biodiversity Framework and the 2050 Vision for Biodiversity.
I am yet to see how the “transfer of technology” can happen truly at a global scale with varying capacity and access to resources around the world. From personal experiences, I can tell that different funding schemas in Europe and the U.S. also make it difficult for cross-continental and international resource sharing and infrastructure building projects.
The framework talks about 23 action oriented targets that need to be implemented. Target 20 mentions joint technology development and joint scientific research programmes (emphasis mine):
Strengthen capacity-building and development, access to and transfer of technology, and promote development of and access to innovation and technical and scientific cooperation, including through South-South, North-South and triangular cooperation, to meet the needs for effective implementation, particularly in developing countries, fostering joint technology development and joint scientific research programmes for the conservation and sustainable use of biodiversity and strengthening scientific research and monitoring capacities, commensurate with the ambition of the goals and targets of the framework.
Target 21 has explicit mentions of “data” (emphasis mine):
Ensure that the best available data, information and knowledge, are accessible to decision makers, practitioners and the public to guide effective and equitable governance, integrated and participatory management of biodiversity, and to strengthen communication, awareness-raising, education, monitoring, research and knowledge management and, also in this context, traditional knowledge, innovations, practices and technologies of indigenous peoples and local communities should only be accessed with their free, prior and informed consent, in accordance with national legislation.
It is good that the text separates data, information, and knowledge. This also aligns with our goal of supporting FAIR and Open data for a diverse set of stakeholders. The term “infrastructure” is missing. The idea of “knowledge management” captures some of the socio-technical aspects of infrastructure. A few more details are in the draft action items in the section entitled “STRATEGIES TO ENHANCE BIODIVERSITY KNOWLEDGE MANAGEMENT ” where several of our collaborators are mentioned.
Knowledge generation and synthesis encompass the creation and advancement of new knowledge and the building of an evidence base, primarily through research and academic initiatives, as well as analysis of information provided by Governments, relevant organizations and other sources. Examples of organizations and processes contributing to the generation and synthesis of biodiversity-related information and knowledge include university research institutions, GEO-BON, IPBES, global assessments by the Food and Agriculture Organization of the United Nations (FAO), UNEP-WCMC and others.
Knowledge generation and focusing on these organisations are great steps. But infrastructural thinking brings out the hidden elements that are needed to design, create, and most importantly maintain the resources for knowledge management.
And it is heartening to see the acknowledgement of metadata and infrastructures like GBIF in the draft decisions:
The knowledge generated or collected must be organized, catalogued and mapped using appropriate metadata and descriptors for easy searchability, accessibility and retrieval. Key players, such as GBIF, GEO-BON, InforMEA and UNEP-WCMC, have developed standards that can be further elaborated and shared. Increasing access to information can be addressed by ensuring full and complete metadata tagging, including subject tagging of knowledge objects. Consistent use of shared terminology increases findability, as does full-text indexing. Increasing the interoperability of search systems and standardization and the use of common descriptors will allow for better findability of information
Even though TDWG (Biodiversity Information Standards) and the FAIR (Findability, Accessibility, Interoperability, and Reusability) or CARE (Collective Benefit, Authority to Control, Responsibility, Ethics) principles are not explicitly mentioned, we do see here understanding of metadata, shared terminology and other aspects of FAIR. Target 1 mentions “respecting the rights of indigenous peoples and local communities”.
There are mentions of “effective collaboration, cooperation and coordination among Governments and relevant organizations in biodiversity data, information and knowledge processes”. This is important for research infrastructures. Also “Alliance for Biodiversity Knowledge” is mentioned in the draft decisions document as an “Informal network”. But we need to see how these collaborations can help with the targets and align them with the operational activities of the research infrastructures.
Data standards came up a few times in the strategic action draft document where again the idea of “findability” and “interoperability” is highlighted without explicitly mentioning FAIR:
Continued improvement of metadata quality, tagging and mapping of knowledge objects from biodiversity-related conventions through InforMEA and other sources to allow for increased findability.
Development, publicization and promotion of standards for metadata quality and tagging of biodiversity information and knowledge resources to ensure quality and compatibility.
“Implementation of the framework and the achievement of its goals and targets will be facilitated and enhanced through support mechanisms and strategies under the Convention on Biological Diversity and its Protocols, in accordance with its provisions and decisions adopted at COP-15.” — How will this transfer into the priorities of each research infrastructure and various European projects? There are specialisations and expertise (for instance from specimen management, sensors, eDNA and digital twins) that bring own challenges of data integration and linking. How would these data issues interface with CBD and its Protocols?
Do we need to take stock of how different research infrastructures and projects responded to the 20 Aichi Targets before we embark on this? One of the early criticism of COP15 is the implementation mechanism are too weak and there are no clear plans. Maybe the infrastructure and data level thinking can help with this.
There’s still a lot to unpack. And I can imagine coming up with such texts in a collaborative environment is not easy. But on the positive side, we have global attention on biodiversity now (even though sometimes this gets overshadowed by “climate change”). Governments and financial organisations are paying closer attention. This is a great time for projects like DiSSCo and other collaborators to take this impetus and contribute to strategic actions.
https://doi.org/10.3897/biss.6.90987 “Human and Machine Working Together towards High Quality Specimen Data: Annotation and Curation of the Digital Specimen”. We are excited to share our proof of concept around community annotation and curation service with a focus on data quality checks. This talk is part of SYM05: “Standardizing Biodiversity Data Quality”. SYM05 will start Tuesday at 09:00 EEST.
https://doi.org/10.3897/biss.6.91168: “Zen and the Art of Persistent Identifier Service Development for Digital Specimen”. No, we won’t be talking about Zen philosophy here. The title is a nod to the 1974 book Zen and the Art of Motorcycle Maintenance. This talk (part of the LTD14 session entitled “Ensuring FAIR Principles and Open Science through Integration of Biodiversity Data”) will feature our current local Handle server setup and persistent identifier for Digital Specimen and related metadata work. LDT14 will be held on 18th Oct Tuesday, between 14:00-16:00 EEST.
https://doi.org/10.3897/biss.6.91428 “Connecting the Dots: Joint development of best practices between infrastructures in support of bidirectional data linking”. This talk will focus on our work in the BiCIKL project highlighting the best practices for reliably linking specimen collection data with other data classes. All three above talks have FAIR Digital Objects as the key focus. More on that is below. Connecting the dots is part of SYM09: “A Global Collections Network: building capacity and developing community” (Thu, Oct 20, 09:00-10:30 EEST).
https://doi.org/10.3897/biss.6.94350 “DiSSCo Flanders: A regional natural science collections management infrastructure in an international context” (part of SYM08: Monday 17 Oct 11:30-12:30 EEST) and https://doi.org/10.3897/biss.6.91391 “DiSSCo UK: A new partnership to unlock the potential of 137 million UK-based specimens” (part of SYM03: Thu 20 Oct 14:00-16:00 EEST). Both of these will highlight national level initiatives that are doing some amazing work on scaling up digitisation, data mobilisation and implementing FAIR principles.
https://doi.org/10.3897/rio.8.e93816 “From data pipelines to FAIR data infrastructures: A vision for the new horizons of bio- and geodiversity data for scientific research”. In this presentation, we will touch upon how from various data pipelines and data aggregations, we can go to the next step of machine actionability — A FAIR (Findable, Accessible, Interoperable, and Reusable) and Fully AIReady data infrastructure that can support pressing research questions. Check out the full program for exciting keynotes and panels.
Within the openDS working group, we are focusing on how the different digital objects and their relationships should look like — Digital Specimen, Annotation, and Media objects. All of these are FAIR Digital Objects with their own persistent identifiers (Handle), PID Kernel, and structured serialisation (JSON and JSON-LD). We are paying close attention to the existing Darwin Core and ABCD elements in use, the ongoing work with MIDS to ensure the reusability of existing efforts. We also had several conversations that provided feedback on the new GBIF data model and we are exploring various pilots to see how DiSSCo and GBIF can help each other.
The data modelling work is a community effort and often takes time to reach a consensus. So we are taking a two pronged approach. First, continuing our regular working group meetings within the DiSSCo Prepare project and keep other outside stakeholders informed. We need this focused effort to fine tune the details. Second, as the data model is evolving we are taking an agile and DevOps approach to test and deploy the infrastructure. Over the past few months, we have deployed a robust test implementation of the DiSSCo Digital Specimen architecture following modern data and software architecture principles with FAIR and FAIR Digital Objects in mind. We will share some of these developments during TDWG and in this space as well.
CMS Roundtable 🦜
On Oct 10, we organised a virtual roundtable inviting several Collection Management System (CMS) vendors, developers to think about how local data systems can interact, integrate or make use of the envisioned DiSSCo infrastructure. For a technical background, please check out DiSSCo Prepare report D6.1 (“Harmonization and migration plan for the integration of CMSs into the coherent DiSSCo Research Infrastructure“) where we talked about API integration and Event Driven Design. The report summarises a previous workshop we did on Event Storming. The CMS roundtable is a follow of this workshop to get more feedback from the community. We had a lively discussion around the future possibilities and challenges. A report and future undertakings based on this roundtable will be available soon.
DiSSCo will be working with both bio and geo-diversity data. There are already several European and global efforts going on (such as GeoCASe and Mindat) that are using existing data pipelines from museums via BioCASe and ABCD Extension for Geosciences to mobilise minerals, rocks, meteorites and fossils. We are working closely with several different stakeholders (software developers, data managers, and collection managers) to understand current strengths and gaps. More on this soon.
Why it matters more in the age of AI and Machine Learning
One of the key concepts outlined in the 2016 FAIR principle paper is “machine-actionability”:
..the idea of being machine-actionable applies in two contexts—first, when referring to the contextual metadata surrounding a digital object (‘what is it?’), and second, when referring to the content of the digital object itself (‘how do I process it/integrate it?’). Either, or both of these may be machine-actionable, and each forms its own continuum of actionability.
Wilkinson, M., Dumontier, M., Aalbersberg, I. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data3, 160018 (2016). https://doi.org/10.1038/sdata.2016.18
Since then, different interpretations and applications of machine-actionability has appeared. However, in recent times, with growth of data repositories, data silos, new architectures principles (such as Lakehouse and Data Mesh), critique of large scale AI models the continuum of machine-actionability is ever expanding. And even with the larger scale and higher volume, the question remains the same. We still need to know “what is it?” and “how do I process it/integrate it?”. We still need to understand and process each data element (the different digital objects) with “minimum viable metadata” and do operations on them — this could be image recognition program that distinguishes a husky from a wolf or diagnosing cancerous cells. The attributes and context of the individual artefacts matter. As we are expanding the scale and usage of AI and Machine Learning, this matters even more now.
And furthermore, even though machine-actionability might imply minimal human intervention, the operations and results of these actions have real world implications. Along with precise definitions and semantics, the context and provenance will become more and more relevant. The husky vs wolf example often time used to show the bias in model training. The original research was designed to see how human users react to such errors and how to create confidence and trust in AI models. In order to go towards such trustworthy system we need to understand the implications and implementation of machine-actionability.
FAIR and FAIR Digital Objects can play a significant role in creating such confidence and trust. In particular when it comes to open science and data intensive research. To begin with, precise definitions and formal semantics are essential. Along with that capturing the context and provenance can tell us why, where, who and when. All these are building blocks that can make data and information “Fully AI-ready” (another interpretation of the FAIR acronym). This readiness needs to be a modular approach instead of a one size fits all. At the same time, we need to provide an open and standard framework for better interoperability. A recent paper entitled “FAIR Digital Twins for Data-Intensive Research” by Schultes et al. proposes such modular approach to building systems based on FAIR Digital Objects. DiSSCo is also working on similar efforts. Some of these ideas also be explored in the newly launched Biodiversity Digital Twin project.
We welcome you to engage with us and think through these topics at the first international conference on FAIR Digital Objects. This event will be on Oct 26-28 (2022) in Leiden — 2022 European City of Science. More information about the conference is here. Hope you see you in Leiden!
A news story published on Aug 6, 2020, in The Verge had the following to say: “Sometimes it’s easier to rewrite genetics than update Excel“.
The story was about a known problem where Excel by default converts gene names to dates . You can try this out at home with the gene symbol “MARCHF1” — formerly known as “MARCH1”. If you type “MARCH1” in an Excel cell, it converts it to “Mar-01”. The HUGO Gene Nomenclature Committee published guidelines in 2020 to work around the Excel issue. However, according to a 2021 study, the problem persists and the authors concluded: “These findings further reinforce that spreadsheets are ill-suited to use with large genomic data.”
But it seems we still cannot stop using Spreadsheets. Recently, a Twitter thread discussed the issue of using Spreadsheets for collections data and metrics. In this post, I try to summarise a few key points from that thread. The goal is partly to appreciate the hold Spreadsheets has in our lives but at the same time to acknowledge that we probably do not have to take a drastic measure as “rewrite genetics”, maybe a few best practices can help us use our tools better.
The twitter discussion started when a curator posted this:
Hey collection users! Please be considerate w/ curators & collection managers. There’s too few of us & we do the best we can to make specimens accessible on a timely fashion. Thanks!! pic.twitter.com/mWSUeMUB50
Same! The more we have online the more requests we get. And the more equipment we have the more requests we can do. We track requests in a spreadsheet 😬
And the conversation soon veered into other domains about recording loan requests, visits, walled/commercial software.
I highly recommend a shared spreadsheet so you can do annual tallies. We record tours curatorial gives too. And images sent. (And I keep an additional count of Microsoft images vs basic labels/sheets with a DSLR. Microscopy can take me a full day for 12 good images)
The gist of the conversation can be summarised as such: Besides the vast amount of scientific data we store in our collections and the various links to molecular, historical and other data types, we also have transactional and provenance data. For instance, digitisation, loans and visits requests. For a lot of us, these requests and subsequently the importance of these requests and the objects are hidden (often in Spreadsheets and Emails). And as a result, we cannot fully comprehend the time and effort it takes for processing these requests and the curatorial activity that happens behind the scene. This has a direct impact on how scientific data is used and shared. The more time it takes for curators and institutions to process this request, the more time it takes for the researcher to get the data. The more these efforts are invisible, the less funding and resources are allocated and as a result, slows down the data production lifecycle.
Oooh that's a good point re invisible curatorial work. Management thinks that collections are dead objects but do not recognise the resources that is required to curate/maintain these 'dead' objects.
There be a reminder of what collections are. Not just pretty dead objects or dusty objections of hoarders. Metrics are imperfect but necessary. Collections are not static; it's dynamic. On the outside it just looks like a building/room/cupboard, but 'neath it lies richness
Some of these issues related to data curation work have also been raised in this paper : Groom, Q., Güntsch, A., Huybrechts, P., Kearney, N., Leachman, S., Nicolson, N., Page, R.D., Shorthouse, D.P., Thessen, A.E. and Haston, E., 2020. People are essential to linking biodiversity data. Database, 2020.)
How do we get these hidden data out of the Spreadsheets and make them usable and FAIR? There are various initiatives (like ELVIS in DiSSCo) that are trying to create services and infrastructures that can allow us to build abstraction layers to share these hidden metrics better.
There is a small bit of movement in this direction for members of @arctosdb We are working toward developments that would allow assertions from “outside” sources for some data. First up, related object identifiers with @GlobalBiotic 🤞🏻
We are not there yet. In the meantime, however, it is important to understand that tools like Excel are easy to use. It is cheaper than large enterprise database systems or large scale European projects. And of course, there’s also the resistance to change. When we use a tool for a long time with relatively good results (unless you are dealing with gene names!), it’s going to be hard for us to switch. There are also other issues such as creating and maintaining APIs and interfaces that need to be in place for the data elements to be useable.
This is not to sing the praise of Spreadsheets but we need to acknowledge the ubiquity, and ease of as we move forward to a FAIR data ecosystem. Instead of trying to change the genetic codes of our data and workflow, we need to find better ways to collaborate and share ideas (as we did in the Twitter thread!).
Persistent identifiers, their links to other identifiers and various contextual data are essential components of the DiSSCo architectural design. Here is a brief example to demonstrate the importance of these identifiers, linking them and providing enough contextual information to perform operations on the digital specimen objects. The example here also highlights some of the challenges we are facing regarding standards mapping and interoperability.
At Naturalis, we are currently adding images to some of our bird’s nest specimen data. Here’s one nest for the bird Turdus merula merula (common blackbird, merel in Dutch).
We have data about this specimen in the museum portal and also in GBIF. However, we start to see some challenges while trying to find these specimens and link them. The museum system describes the nest using the ABCD schema with the following two terms: “recordBasis”: “PreservedSpecimen” and “kindOfUnit”: “nest”. recordBasis maps to the Darwin Core term basisOfRecord but kindOfUnit does not map to any terms (FYI: there is a mapping schema and the community is aware of these issues). As a result, searching for nests of Turdus merula merula can only be done from the Naturalis bioportal. Even though the GBIF record points back to the museum record, from the museum record we cannot get to GBIF. Other museums are using the field dynamicProperties. Here’s an example of a nest from NHMUK (this is a good example because it shows bi-directional links). As different standards and systems are involved in the data management and publishing pipeline that are not fully interoperable, we lose the context. Again, we are well aware of these problems. And various initiatives are currently addressing these issues from different data points.
For this example, I created a simple Digital Specimen. It has a persistent identifier and enough contextual information to tell us that this is a nest, not a bird specimen. It also shows that the collector is “Max Weber” (not the famous sociologist) but Max Wilhelm Carl Weber, a German-Dutch zoologist.
Screenshot from Bionomia that uses wikidata and gbif identifiers to connect specimens to collectors. source: https://bionomia.net/Q63149
To learn more about the elements and the structure of Digital Specimen please check out the openDS repo. The python codes of this example are available in this notebook.
This simple example shows the value of identifiers (such as Handle, ROR, Wikidata) that can help link various contextual information to make these specimens FAIR. In the coming years, DiSSCo with others will tackle some of these challenges.