DiSSCo envisions discovering the untapped value within vast natural science collections across Europe and aims to connect these collections to related datasets and new insights using the FAIR Digital Object (FDO) framework. A key milestone toward this vision is the development of various data models and services that can help annotate and publish digital specimen data. This allows for the enrichment, correction, and improvement of digital specimen information, not only through manual annotation but also with batch and AI-assisted services.
During our design and test phase, we considered how these new annotation digital objects can integrate into the existing biodiversity data ecosystem. We align with ongoing discussions on open Digital Specimen (openDS) and MIDS, emphasising FAIR implementation. This approach ensures seamless collaboration and leverages existing models, ontologies, and specifications.
Now, let’s delve into the background, showcase an example, and explore the data model.
The concept of web annotation or scientific data annotation is not new. The World Wide Web Consortium (W3C) annotation data model (WADM), at the forefront of this collaborative endeavour, establishes the foundation. Drawing inspiration from the International Image Interoperability Framework (IIIF) and Europeana Annotation Data Model, both of which also build upon the W3C framework, we adopted WADM as our starting point. This ensures that annotations in the biodiversity domain align with global standards, fostering interoperability and enriching the scholarly landscape.
The topic of annotation regarding natural science collection and biodiversity data is also not new. The community has been working on this from various perspectives (see activities of TDWG Annotation IG, tools like AnnoSys, Pensoft Annotator; also see recent publications like Morris et al. 2023, Stork et al. 2019). Our approach builds upon these previous works, emphasising FAIR implementation and FDO Framework.
In Fig 1, we see the core WADM framework, which serves as the starting point for thinking about how annotation and digital specimens can be integrated. Annotation is always carried out on something — the “target” in Fig 1. In DiSSCo’s case, the target can be a digital specimen, a media object, or another annotation object. The body represents the content of the annotation and these components are linked.

Let’s consider an example involving a herbarium specimen (Fig 2), where a deep learning model can be employed to annotate and detect plant organs. Each of these boxes can serve as part of the annotation target. Picture a user drawing a bounding box, adding comments or making corrections to the content. This process can be applied to images or various data points such as collector’s names and locations. Additionally, we aim to accommodate both single-user interactions and batch processing. Our current sandbox implementation includes some of these features, ready for testing, and we hope to iteratively enhance them.

However, we need a framework — a data model — to capture annotations alongside specimen data and ensure FAIRness. Specifically, we need a flexible approach that accommodates commenting, editing, and data improvement. Fig 2 above illustrates the overall structure of our Annotation data model, incorporating concepts such as motivation, target, body, creator, and generator from WADM, and AggregateRating from schema.org. We introduce a few new terms as needed.
Let’s delve into this model in more detail. Picture a LEGO set, each piece designed to contribute to the grand structure. In Fig 3, observe the unique identifier (ID), type, and motivation of the annotation — defining its essence and purpose within the structure.
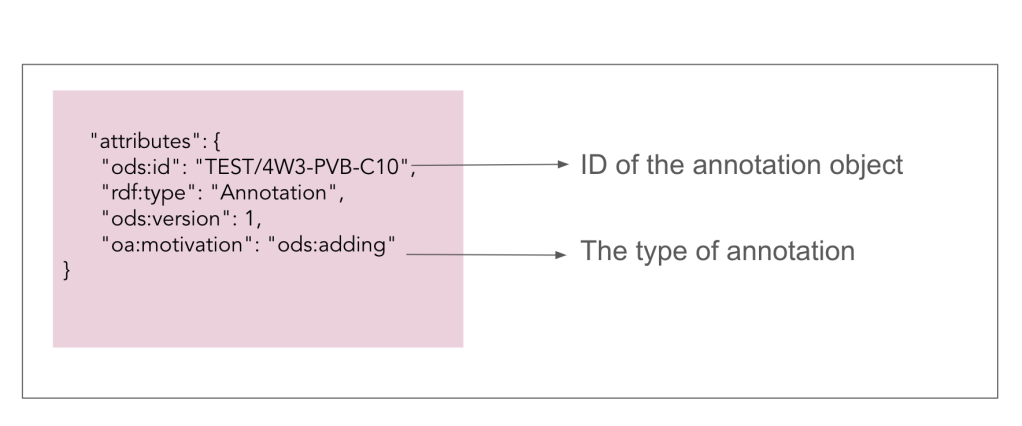
Fig 4 shows a crucial element: the target of the annotation — essentially, the object being annotated. This could be an entire image, a digital specimen, or a specific field.

Finally, in Fig 5, there’s the body — the content encapsulated within the Annotation object. Here, we showcase the value — this could be an addition, comment, or an assessment (based on the selected motivation displayed in Fig 3). Another crucial aspect for tracking provenance is identifying who created this annotation — this could be a human or a machine agent.

Our model is designed with flexibility in mind to capture different types of annotations. We are also planning to integrates this into approval/rejection workflows. Additionally, this structure facilitates linking and exporting of data to various systems, whether through bulk export or API operations. This adaptability ensures our annotation framework is versatile and aligns with diverse operational needs and collaborative workflows.
This process of data modeling and design is a collective effort. Many thanks to the core DiSSCo development team at Naturalis Biodiversity Center (Wouter Addink, Sam Leeflang, Soulaine Theocharides, Tom Dijkema). We also gathered responses through an RFC (Request for Comments) process, where feedback and insights shaped our thinking, paving the way for further improvement. Excitingly, several new features are in the pipeline. For more details, check out our GitHub and sandbox. Happy annotating!

This is a fine-grained and admirable annotation proposal and I hope it comes into use. But does DiSSCo intend that it will replace direct contact between data users and participating institutions? For example, an email that points out to the institution’s data manager an error of the kind highlighted in the [Darwin Core tablechecker](https://www.datafix.com.au/darwin-core-checker/) that affects numerous records. I appreciate that in both cases (errors documented in a public annotation, and errors documented in a private email), the institution may not act to fix the error. In that case the annotation is a useful public warning to end users. Another question: does DiSSCo intend that annotations will replace the need to preview and edit the records from participating institutions? In other words, is it now DiSSCO policy that it will serve unchecked data as digital specimens, and leave any editing or corrections to an annotation process?
LikeLike
Hi Robert, sorry for the late reply.
>>does DiSSCo intend that annotations will replace the need to preview and edit the records from >>participating institutions? In other words, is it now DiSSCO policy that it will serve unchecked >>>data as digital specimens, and leave any editing or corrections to an annotation process?
No, annotations are not intended to replace the need for previewing and editing records from participating institutions within DiSSCo. Annotations serve as a mechanism to correct errors and enhance data quality. They act as a vehicle toward achieving greater FAIRness and improved data quality. As you rightly pointed out, annotations can also serve as valuable public warnings for end users. However, they do not replace the original record in the local institution’s catalog. We are also exploring how annotations, depending on factors such as their quality and the credibility of the annotator, can be vetted and integrated into the primary digital specimen record as accepted values. This integration ensures that all provenance is linked with PIDs and eventually incorporated into the local collection management systems.
LikeLike
Hi, Sharif.
Many thanks for those clarifications, and I look forward to hearing how DiSSCo will vet the annotations. I would also love to see a post (like this one on annotations) explaining just how DiSSCo will preview and edit records from participating institutions, and whether those edits will have priority over annotations for the institutions.
LikeLike
Please see also
https://discourse.gbif.org/t/filtering-isnt-cleaning/4108/21
LikeLike